


The following is a guest post written by Dave Farinelli.
Updated July 2, 2025
Feature flag deployment is gaining popularity as a way to provide safer and more effective deployments for teams looking to streamline their deployment pipeline. Feature flags simplify the process of making more frequent deployments by allowing granular control of the functionality deployed based on the environment.
What Is a Feature Flag Lifecycle?
A feature flag lifecycle refers to the stages a feature toggle goes through—creation, testing, deployment, activation, and retirement. Properly managing this lifecycle is key to minimizing technical debt and ensuring safe rollouts.
As a refresher, a feature flag (also called a feature toggle) modifies software functionality without requiring a redeployment, effectively allowing for dynamic and easy configuration of software. Some of the perks of being able to do this include:
- Experimentation: The ability to turn on certain features for a subset of users to determine the reception of new features.
- Safer deployments: The ability to turn off the effects of a deployment quickly, in case a rollback of functionality is required.
However, by nature, feature flags introduce complexity into a software development lifecycle and have inherent risks for teams not managing said complexity appropriately. The main culprit of this comes in the flag debt, or an overabundance of feature flags, which causes cognitive overload, which in turn translates into further technical debt and increased risk in further deployments.
In this article, I’ll go over the general lifecycle of a feature flag, from creation to retirement, to help with managing feature flag complexity and allow your team to get the full benefit of using feature flags.
Step 1: Creating Feature Flags for Safe and Scalable Deployments
The first step when considering new functionality is to determine the type of feature flag that will be created alongside the deployment. There are a number of general categories when considering the creation of a feature flag:
- Release toggle: Useful for teams using continuous delivery. Release toggles essentially keep new functionality hidden in deployments while allowing for changes to be committed to the main branch. These toggles typically are kept off until functionality is ready for release.
- Experiment toggle: Allows for turning on and off completed functionality specific to environments. This is useful when using A/B testing or Canary releases. For example, in a load-balanced system, you may choose to use two workflows and randomly assign users to each, then collect data from their experiences and determine the best way forward.
- Ops toggle: Serves as a “circuit breaker” of functionality to accommodate for potential infrastructure issues. For example, if an external service has unplanned downtime, this might be a long-lasting feature flag that gracefully deactivates functionality in your software.
- Permissioning toggle: Allows for turning functionality on and off based on a particular subset of users. Unlike Experiment toggles, Permissioning toggles are based on a specific set of users and are usually meant to be long-lasting.
When considering a feature flag, the most important thing is to think about the following traits:
- The longevity of the feature flag and how long it is expected to be in use.
- The dynamism (or ease of configuration) of the feature flag, alongside which the team needs to be able to invoke changing of the feature flag.
Plotting that on a table, it breaks down to the following:
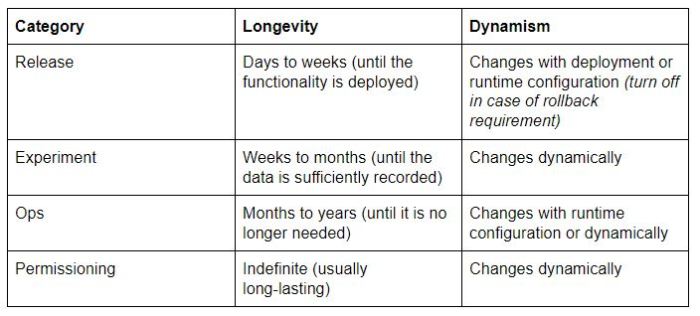
Using the information above will help with being able to determine how a feature flag will be used when deployed into production. For instance, general functionality that will stay static when deployed will be a Release flag, whereas functionality to “short-circuit” features will be an Ops feature flag, changing the overall implementation.
Once the feature flag is created, the next step is getting it into place—which leads us to the next section of deployment.
Step 2: Deploying Feature Flags Across Environments
After the creation of the feature flag, the next step is getting the feature flag into upstream environments as quickly as possible. By getting the feature flag in place, you’re able to control the environment dynamically, even with the functionality being incomplete.
No matter what type of flag is in place, getting the flag set up in all upstream environments is key, as it allows for using the feature flag functionality for the granular control it provides. Remember that the feature flag and the functionality do not need to be bundled together. For example, if there is functionality in place that may take weeks to get to a working state, you would be well-served to spread out the complexity of the deployment by deploying the feature flag as soon as possible.

Once the flag is in place, the next step is using it!
Step 3: Activating Feature Flags in Production
The third step in the implementation of a feature flag is activating functionality in the production environment. This is where feature flags shine—now, instead of having a deployment and hoping everything works well, you just turn things on when you’re ready to start using said functionality.
In step one, creation, we talked about the dynamism of flags and the capability of turning them on and off. Especially for Ops and Permissioning flags, it’s important to be able to quickly change their state with ease. A tool like CloudBees Feature Management can provide an easy way to set flags to be easily changeable, while providing a dashboard to manage them easily.
Finally, let’s address different scenarios when thinking about different testing strategies:
- One in which a team uses a standard testing environment (for example, development → staging → production).
- Another in which a team uses minimal environments and uses continuous delivery into a single production environment while performing testing in production.
For a team with multiple environments for testing, this allows for setting feature flags based on the environment, allowing for using feature flag functionality across different environments. For instance, a deployment could deploy to both staging and production environments, then clone production data into the staging environment. Setting the feature flags in the staging environment to test new functionality can ensure functionality with real-time data.
Because feature flags are useful, many of them will reach a point where they are no longer required. Once that’s the case, we’ll move on to the final step of the feature flag lifecycle.
Step 4: Retiring Feature Flags to Reduce Technical Debt
The final (and very important!) step in the use of a feature flag is the retirement of it, effectively merging it into the standard codebase. I touched on this a bit in the introduction but want to reiterate here the importance of the lifespan of feature flags, and the importance of pruning them after their use is no longer required.
With the use case of feature flags being a way to configure environments, it will cause issues when there are too many ways to configure an environment. Each feature flag provides an opportunity for misconfiguration, and having too many in place causes a lot of cognitive load for those running configuration, which eventually causes issues down the road.
The solution to this? Make a process in which feature flags are regularly retired and removed from the codebase. This will result in deployments that just remove feature flags and cause certain features to become standard in the codebase. For something like Release flags, this will usually be done quickly after a successful release. Experimental flags will be retired after successful data is collected, and Ops and Permissioning flags may end up sticking around in the long term.

Managing the Feature Flag Lifecycle from Start to Finish
Hopefully, this guide helps with putting the feature flag lifecycle in perspective, giving you the means to understand how to use them with your software solutions.
You may be thinking, how do I get started with all of this? It’s common to be in a situation where developing an in-house solution for flag lifecycle management is just not a feasible option for your team. A lot of the time used in determining the right solution represents time taken away from developing features for your customers, and without the knowledge of what you may need in a feature flag management solution, you may end up missing important details. More commonly, what happens in these scenarios is that, fueled by good intentions, a solution is started, but is never actually able to solve for having a commercial feature flag management solution.
There are plenty of solutions that allow for quick integration of a feature flag-based deployment model for your codebase, including CloudBees Feature Management product. This will help you get started quickly with using feature flags, without having to add more work in rolling out your own solution, especially if you’re starting from scratch.
Dave Farinelli is a senior software engineer with over eight years of experience. His specialty is in providing enterprise-level solutions for healthcare and insurance clients. Dave holds a B.S. in computer engineering from Kettering University in Flint, Michigan.


