

I will assume you are at least familiar with the concept of microservices -- loosely coupled services that provide discrete solutions to business use cases that you can combine to solve current needs and demand. The architectural pattern has gained popularity over the past years, and although not everyone is completely sure what "doing it right" looks like, it's a concept that suits modern needs and is here to stay for the foreseeable future.
I help organize the Write the Docs (a global community for those interested in technical documentation) group in Berlin. Over the past month, multiple people asked me about what tools and practices I recommend for documenting microservices and application architectures that use the pattern.
Some light Googling later, I found others asking the same question, but no concrete recommendations, so thought it was time to set ideas down. I intend this post to set out the problem, pose some solutions and provoke discussion for those in the field. These are merely my musings, but together we can determine what best practice might be, and create ideas for actual tooling to help.
Defining the Problem
Each microservice is in essence a "typical" application. In many ways, you can follow standard best practices for documenting each of them (and if you need help with that, I recommend my 'A Documentation Crash Course for Developers' post). In my opinion, the area where developers are stuck is visualizing and documenting how the microservices interact.
Topic-Based Documentation
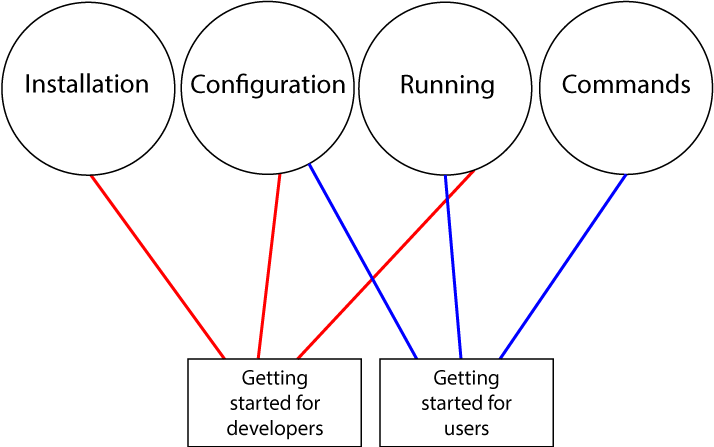
Before we move into forward-thinking, I want to take you all back into a documentation practice that has existed for some time but has potential use here, at least conceptually. Topic-based documentation breaks documentation down into discrete concepts (topics) that you can then assemble to suit particular documentation use cases.
For example a Getting Started guide for developers might combine installation, configuration, and running topics. Where a Getting Started guide for users might combine configuration, running, and commands topics. As you can see, it combines discrete content items to suit different use cases. Sound familiar?
Note that the traditional tooling for topic-based documentation may not be entirely appropriate for this use case, as it's often expensive, proprietary, and in itself, monolithic. However, we can certainly borrow elements of the idea and tooling.
Display All Endpoints
In this Stack Overflow post, the poster asks how to display all endpoints across all services, no matter which services are public, active, and which endpoints within them are the same. Using the approach set out above, we could create a page that queries all our services marked as active and public, and all the endpoints within that are the same. If you add or remove a service or endpoint, then the page will update to reflect this.
Display Intersection of Endpoints
A more complex need might be showing how the services interact at an application level. A service calls another service using an endpoint, joined by a parameter. Or to put it another way, the user service queries the order service to find out the orders a user has made, using their user ID to query.
!Sign up for a free Codeship Account
Endpoint Explanation
Great, but so far this approach is purely about demonstrating endpoint functionality. What about the conceptual explanation of how these fit together in a microservice-based application? Again, ideally these snippets of explanation should borrow from the architectural paradigm and the topic-based approach I mentioned, and usable in different and varied contexts.
As with your code, you should consider breaking down these explanations into discrete and reusable components. For example, if a user arrives at your application to see an order status, this could involve several services: authentication, user records, order listings, and order status.
A user arriving to check account details could involve the authentication, user records, and an account service. Therefore, you should keep the conceptual explanation of each of these services separated, likely in the repository of the service. In fact, this is probably what you're already doing.
I propose you add extra snippets of documentation in a "documentation assembly" service that contain details as to how each of the potential intersections work. For example, a file that describes how the user record service calls the order service, and another file that describes how the user record service calls the account service. In such a simple example as this one, including this explanation in the API documentation may be enough, but there may also be times where you need more.
Tooling for the Documentation Assembly Service
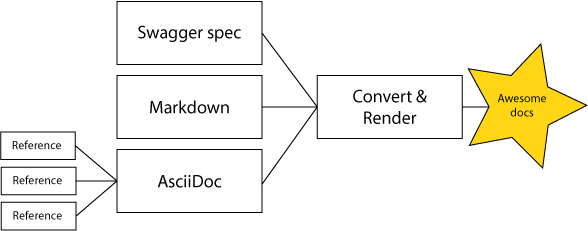
How you handle the assembly of the different sources of information is up to you. Much like in the coding world, the documentation world has a myriad of tooling available, and you decide what suits you best. To suit the microservice architecture, this assembly should be a service itself, and you should consider tooling that can happily run in containers, serverless instances, or similar. Fortunately, documentation generation and hosting is not generally a high-impact service, so is easier to maintain.
No current tooling will do everything for you, so I will present pieces of the puzzle that I feel you could adapt to work well and how they might help. I will also present a handful of alternatives for different markup languages, but will leave further investigation and research to you, the comments section, or get in touch with me.
As most markup languages and API specs are all parsable formats, a competent programmer should also be able to roll their own custom solutions if nothing I present helps.
It's worth noting that there are some commercial services or CMS-like systems that could handle some of these processes for you, but I feel this goes against the microservice mentality.
Conversion
To enable the combination of documentation in different formats to ease management and rendering, you might need to convert to create a unified format.
- Pandoc - One of my favorite tools. Converts between a wide variety of markup formats, but no API specification formats.
- Swagger2Markup - Converts Swagger to AsciiDoc or Markdown.
- API Spec Converter - Converts between Swagger (V1 and 2), Open API 3, API Blueprint, RAML, WADL, and others.
- apib2swagger - Converts API Blueprint to Swagger.
- swagger2blueprint - Converts Swagger to API Blueprint.
- Apimatic Transformer (online) - Converts between a wide variety of specifications including Postman.
- apiary2postman - Convert API Blueprint to Postman.
- Blueman - Convert API Blueprint to Postman.
- apib2json - Convert API Blueprint to JSON.
Transclusion
Transclusion is a term that I use to mean including the contents of one document in another. You might call it linking, inclusion, cross-referencing, or something else. But for our purposes, it will be how we include a variety of sources of information (API references and linking explanatory text) into a series of files for rendering. Many markup languages will do this for you by default, while others will need 'encouragement'.
- Markdown doesn't include other files by default, but you have options with hercule, MultiMarkdown or, as part of your rendering pipeline, a static site generator like Jekyll.
- Asciidoctor is a widely used toolchain for Asciidoc seamlessly handles including other sources.
- reStructuredText can include external files by default.
- If you want to enter the topic-based world, then dita includes cross-referencing for code and text. Docbook has text objects and includes.
Rendering
Rendering your assembled files into HTML, PDF, ePub, or another format is a default behavior of every documentation markup language, so dig into the documentation of whichever format you choose to pick an option.
Create the service(s)
I can't dictate what your documentation service(s) will need, but it should be possible to use containers to manage your dependencies and then a bunch of scripts to check out, assemble, render, and serve documentation. Extra points if you parameter-ize the service(s) to generate different documentation based on what you feed in. For example, toggles to include individual APIs or snippets based on need or use case.
Next Steps
Okay, I admit, I haven't told you exactly what to do in this article. Rather, I presented a series of potential ideas and resources to spark discussion, and you're possibly none the wiser than when you started reading.
However, what else could you throw into the mix? Testing would be an obvious start, and I suggest you read my earlier posts on testing aspects of documentation for more ideas. You could add other services to render documentation in different formats or ways, feed support systems or social media, or create an API for your API documentation. As any microservices fan knows, once you work through the complexities of smashing apart the monolith, the possibilities are endless.


