


Feature flags are one of those engineering tools that seem almost too simple to cause problems. The concept is simple: Wrap a feature in a conditional, flip a switch, and control who sees it without touching a deployment. When you need to roll something back, flip it again. For a small team moving fast, a homegrown version—a config file, a database row, a hardcoded boolean—is often enough to get started.
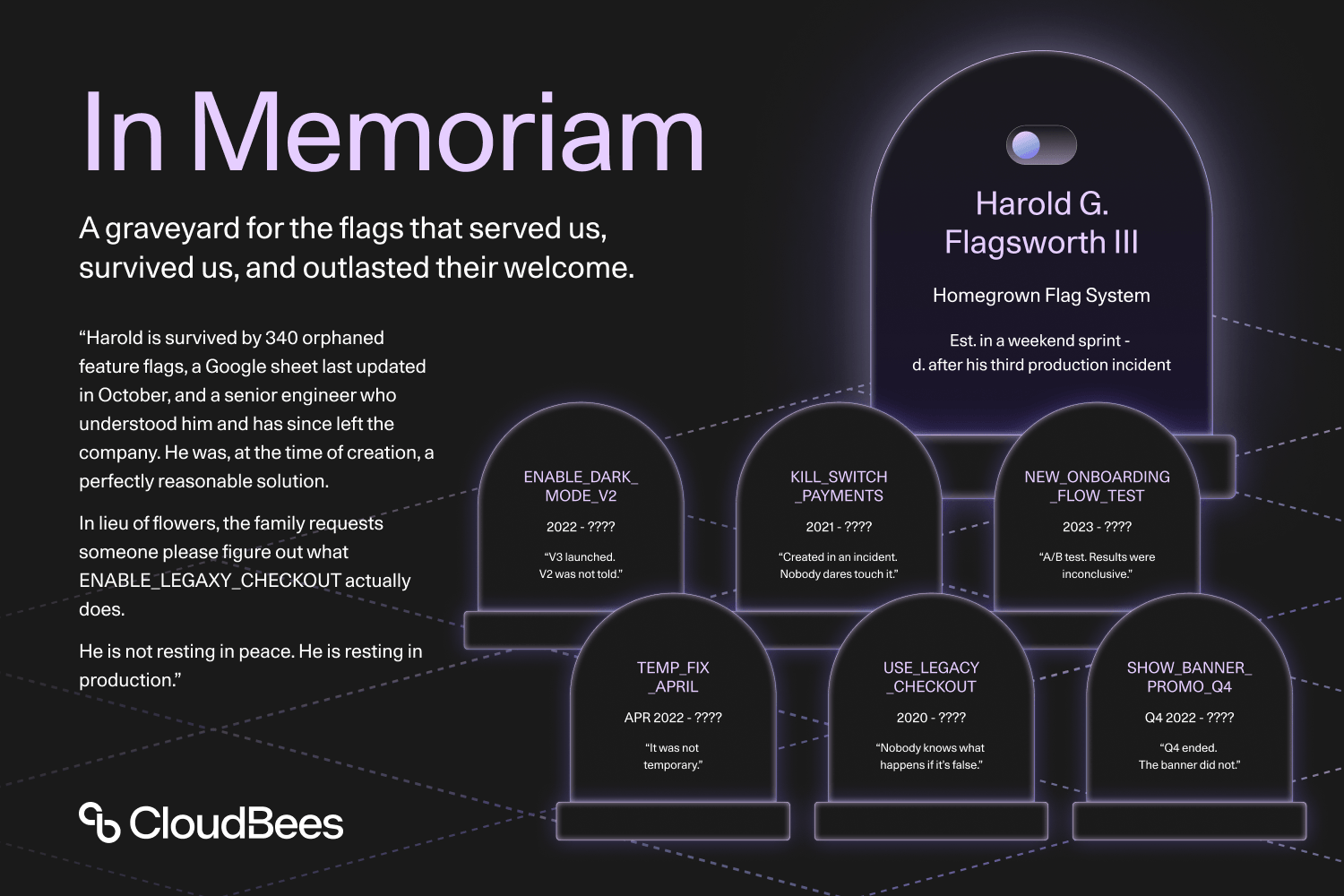
Most engineering teams have built a feature flag system like Harold G. Flagsworth III. And even though the obituary has been written, nobody can seem to pull the plug. The engineer who built him left. The flags he controls aren't documented. And the last time someone suggested turning him off, the room went quiet. Harold is not resting in peace. He is resting in production.
The question is, how long can you afford to keep him around?
Why So Many Teams Build Their Own Flag System
Engineering teams build their own flag systems for the same reason they build most internal tools: the commercial alternatives feel like more than they need. A dedicated feature management platform, with its dashboards, SDKs, and approval workflows, is a lot of infrastructure to adopt when all you want to do is hide an unfinished feature from users.
A small team of engineers who all know the codebase doesn’t necessarily need more than a homegrown system. However, issues emerge as the team grows, the codebase expands, and the flags accumulate faster than anyone can clean them up.
The question of whether to build or buy a feature flag system rarely gets revisited until something breaks. These breaking points usually occur when the system starts to buckle under volume: more developers committing changes simultaneously, more flags being created across more teams, more stakeholders who need visibility into what's live and for whom.
The Operational Problems That Emerge at Scale
As teams grow and flag counts rise, the gaps in a homegrown system become harder to ignore. AI-assisted development is also accelerating that process. When code generation tools help engineers ship more features faster, the operational gaps in a system built for a smaller, slower team compound faster than expected. Here is where those gaps tend to show up first.
Flag Ownership Dissolves Over Time
The reason feature flags become hard to track across teams is that homegrown systems lack a native governance model. Flags are most often created by individuals rather than assigned to teams.
In many cases, a flag gets created, does its job, and then sits there. Nobody formally decommissions it. The engineer who created it moves on to other priorities or even leaves the company. Over time, teams can find themselves with flags that nobody is confident enough to delete.
Governance Is Hard To Retrofit
When a compliance team asks who changed a flag, when, and why, most homegrown systems have no reliable way to answer those questions. Audit trails are rarely built in from the start; they're the kind of thing teams intend to add later, when there's time.
Approval workflows, role-based access controls, a record of who enabled what and when; these don't come standard in a system assembled from a config file and a few conditionals. By the time a security review or regulatory audit makes them necessary, reconstructing that history from Slack threads and spreadsheets is rarely sufficient or repeatable.
Engineers Become the Only Interface
Homegrown flag systems are built by engineers, for engineers. There is usually no dashboard, permissions model, or direct way for a product manager or release owner to interact with the system.
That works fine when the engineering team is small, and everyone is in the same room. It starts to break down when feature releases involve multiple stakeholders—product, marketing, and customer success—who all have legitimate reasons to need visibility into, or control over, what is live and for whom.
In practice, every flag change becomes an engineering ticket. A product manager who wants to run a controlled rollout to a specific user segment has to write up the request and wait for an engineer to prioritize and execute it. A release owner who needs to reduce exposure to a non-performing feature has no direct way to do so.
The result is a bottleneck that slows release decisions, creates unnecessary back-and-forth, and pulls developers away from higher-value work.
Trigger Events That Make Flag Debt Impossible To Ignore
Operational problems can persist for a long time without forcing a decision. Teams patch around them, absorb the friction, and defer the harder conversation about whether the system is still fit for use.
What sometimes changes the situation is a specific event that makes the cost of inaction visible to people beyond the engineering team. Here are a couple of examples.
A Production Incident Traces Back To an Ungoverned Flag
When a post-mortem points to a feature flag, the questions come quickly. Who enabled it? When? Why? For teams running homegrown systems, those questions are often difficult to answer with any certainty.
In the meantime, the feature remains live, and every minute without a clear answer increases the risk of customer churn or reputational damage. Flag debt stops being solely an engineering problem the moment it has a dollar figure attached to it.
A Compliance Audit With No Paper Trail To Show
Proving control during an audit requires a change history that the system itself can produce. Compliance audits ask specific questions, like who modified a flag, when, and under what authorization. If an external audit uncovers a governance gap before your team does, the potential consequences—fines, failed certifications, lost deals—can be significant.
What connects these two scenarios is the same underlying condition. Homegrown flag systems record state, but not intent. They can tell you a flag is on, not why it was turned on, who authorized it, or what it was supposed to accomplish.
When It's Time to Move to a Dedicated Feature Management Platform
At a certain scale, how a flag system is governed matters as much as what it does. Both a homegrown system and a dedicated feature management platform control what ships, to whom, and when. But a purpose-built platform is designed from the start around a different set of assumptions:
- Multiple people need visibility into what is live and for whom.
- Changes need to be traceable, with a clear record of who did what and when.
- The system itself should be able to answer questions that arise during an incident or audit.
Managing feature flags at scale means more than conventions and tribal knowledge. In practice, it means:
- Every flag has a named owner and a documented purpose, so cleanup is a routine operation rather than a risk assessment.
- Non-engineering stakeholders can interact with the system directly within defined permissions.
- When a compliance team has questions about a flag, the answer is in the system.
Homegrown Harold is still in production. The only question is whether your team decides when he goes, or an incident or audit decides for you.
CloudBees Feature Management (CloudBees FM) is built around this architecture. Every flag has a named owner. Changes are logged with who made them, when, and under what authorization. Product managers and release owners can interact with the system directly, within defined permissions. And when a compliance team asks who enabled a flag and why, the answer is in the system.
Not sure if it's time to move on from your homegrown system? Check out our guide to building or buying a feature flag system.


