

Unless you are in the development stone age and SSHing into the production servers to hand edit files with Vim or Emacs (please keep that flame-war elsewhere), your development environment is not the same as production.

The absolute minimal difference is capacity and load. You can replicate the exact software versions, and perhaps even configurations - modulo the TLS certificates and host names - but your development environment will never have the load of production nor does it have the capacity to handle that load.
There are other times when it is incredibly helpful for the development environment to diverge even more from the production environment, but this is not to say that minimizing the differences between the production and development environments is a bad idea. Developer tooling like Jenkins X with its DevPods allows you to develop your code locally and almost seamlessly run the same code in an environment that is as close as it is possible to get for a Kubernetes application. Certain classes of bugs, especially networking related bugs, can only be identified when you are developing close to production.
If you came looking for a flame war, I'm sorry, this post is not for you.
This post is about celebrating some of the different use cases we encounter during the development process and how these use cases can benefit from targeted differences between the Development environment and the Production environment.
A cautionary tale
Many years ago, at a previous employer, we turned on code coverage in our development builds. The tooling we were using would run the tests twice, once without coverage and once with coverage. Our tests were not unit tests, they were mostly integration tests that were hitting a database, running the tests twice was impacting the build time.
So we turned off the test run without coverage.
Shortly after, a threading bug started to show in QA. The crazy thing was that the bug logically could not happen. We even had unit tests that verified the sequencing of events.
It was only when I happened to run the test suite without coverage that the test failed.
Our development environment had additional synchronization points while the code coverage call counts were being updated. The additional synchronization was sufficient to prevent the sequencing bug... a bug that would have shipped to customers except we were on a yearly release cycle and QA had only started early testing on the first batch of features.
This kind of difference between development and production is not the kind of difference you want!
Use case #1: Database bugs
Sometimes you have a bug that you are trying to trace down. Support have given you a database dump that reproduces the issue, but the dump takes a while to load. Every time you want to test a theory, recheck the fix-up scripts or narrow in on the minimal reproducer, you need to be sure the database is at the exact same place as the dump.
That wipe-load cycle can get tiresome (and we are not even considering having to restart the application in order to purge any caches of the database that may be held in memory.)
You think to yourself: "Hey, the PostgreSQL database is just a Docker image, I can just create a derived image that loads the script and now I just restart the container rather than have to wipe-load"
Except it doesn't work!
Here's the last 10 lines of the PostgreSQL `Dockerfile`:
LANG:dockerfile
ENV PGDATA /var/lib/postgresql/data
RUN mkdir -p "$PGDATA" && chown -R postgres:postgres "$PGDATA" && chmod 777 "$PGDATA" # this 777 will be replaced by 700 at runtime (allows semi-arbitrary "--user" values)
VOLUME /var/lib/postgresql/data
COPY docker-entrypoint.sh /usr/local/bin/
RUN ln -s usr/local/bin/docker-entrypoint.sh / # backwards compat
ENTRYPOINT ["docker-entrypoint.sh"]
EXPOSE 5432
CMD ["postgres"]
The problem is that VOLUME directive. The resulting directory is only seeded when the volume is created. The docker-compose.yml or whatever other local orchestration tool you are using has helpfully assigned a named volume so that data is retained across restarts.
We need a different Docker image for this kind of development: some potential solutions:
- Copy the Dockerfile and remove the VOLUME directive and append the data load; or
- Override the ENV PGDATA /var/lib/postgresql/data to point to somewhere else that is not covered by a VOLUME directive, living with the unused volumes being created and attached.
- Change our container orchestration tool to discard the volume on restart, remembering ito keep this change out of source control.
Use case #2: Authentication
Your application requires that you be authenticated in order to access the UI. Every time you restart the application, the authentication cookie gets invalidated. So testing your changes requires that you type in the username / password almost continuously.
And on top of that first world problem, you need to be able to test with different permission sets, so every so often you have to call your colleagues over and get them to login for you just so that you can see the effects with different permissions.
Yes, it is awesome that the development authentication is against the production authorization service, as now we will know immediately if that is broken... but that's not where the bulk of the changes are. In fact, the authentication code is basically feature complete now.
When I was faced with this problem for the DevOptics service at CloudBees, what I did was to write up a fake authentication service. It is trivial for developers to switch between using this fake authentication service, the real authentication service running in staging and the real authentication service running in production... we default to the fake authentication service.
This service just displays a screen of users with various permissions sets and you click the login button to login as that user. No typing, just one click.
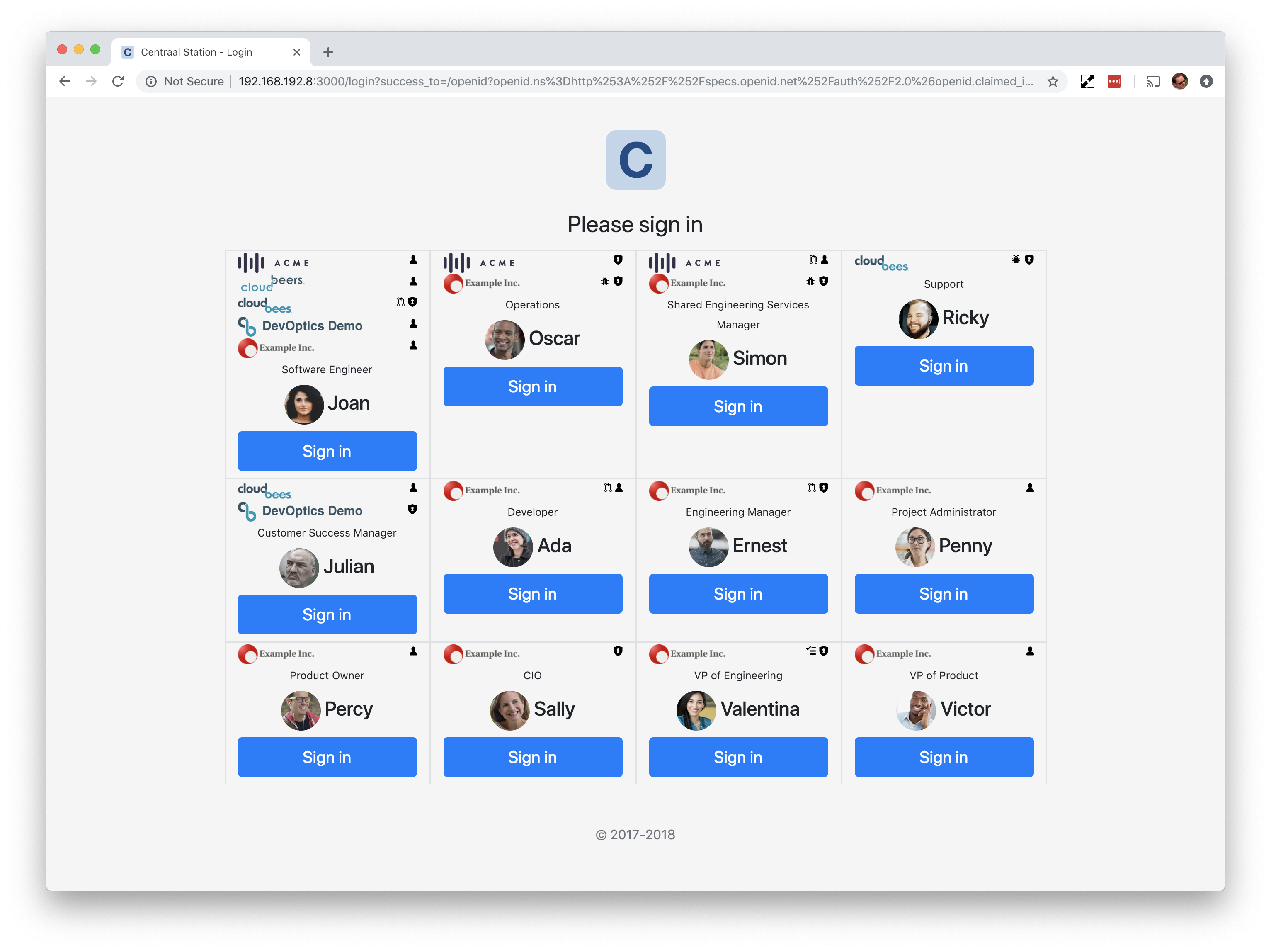
NOTE: Yes, we have tests running on the CI server that use special test accounts to login using the real authentication services, and the mock authentication service container is not even published to our container registry, to ensure that the mock never lands in production.
Use case #3: Memory settings
Some side-car services that you run can be quite resource intensive. For example, tuning the JVM settings for your production Elasticsearch can require a rather beefy machine to run on. If we keep development the same as production, we would be over-provisioning the resources required. In general, a development environment does not require the same scaling as the production environment:
- You don't need a whole cluster, for most features and bugs, a single instance will be sufficient.
- You don't need the disk capacity of production because you will typically only load small data sets.
- You only need between 1-2Gb of RAM allocated to the container.
Precise memory tuning will depend on how your application uses Elasticsearch, but in general, you will have fewer indexes in a development environment because you rarely have enough data to require partitioning across indices.
Conclusion
Hopefully, you agree that there are some cases where you can benefit from intentional differences between development and production.
Additional resources
- Read the lessons learned from a year of continuous deployment
- Why you should know about GitOps


