


Brooke’s law as mentioned in the Mythical Man Month states that adding people to an already late project just makes it later.
All software projects are late. Ask any VP or CEO. Things are never done fast enough, but does that mean that adding people will help, or like the mythical man month will make it later? CloudBees decided to investigate the answer to that question.
This isn’t something you can really do in the real world, you don’t get to do a change twice, nor would it even make sense to try. However, with predictive analytics, we may be able to try an experiment.
How AI-Driven Predictions Become Simulations
This report builds on my previous post, where we we created predictions of what the outcome will be of software delivery work in progress, based on AI models trained on an organisation's past behavior.If we play with the data that drove those predictions (not the training data, but the actual work in progress data) then predictions will change, and we have simulations!
Let’s look at an example - a bunch of work in progress pull requests. This is our current state of predictions:
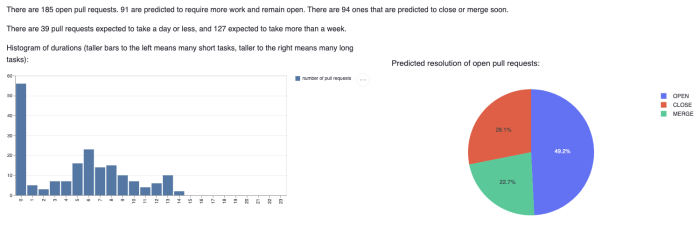
Many of the PRs listed above are predicted to take less than a day, and there is a bit of a “long tail” in the distribution of task durations. There are 91 pull requests predicted to require some additional work. Remember these are predictions but based on using the real data, the current facts in the system.
Adding more people
Let’s play with fire and see how adding people changes the above simulation. In this case, we are adding 11 pretend people to all this work in progress (ouch!):

Ouch indeed. We see above that adding all those new people actually means there would be more work to do and changes are predicted to remain open for longer! This probably isn’t surprising, as people take time to get up to speed typically.
Does this mean we shouldn’t add people to help out with the backlog? (Clearly there is a backlog in this scenario). Not necessarily, In the distribution there is a “shifting left” or bunching up of durations:
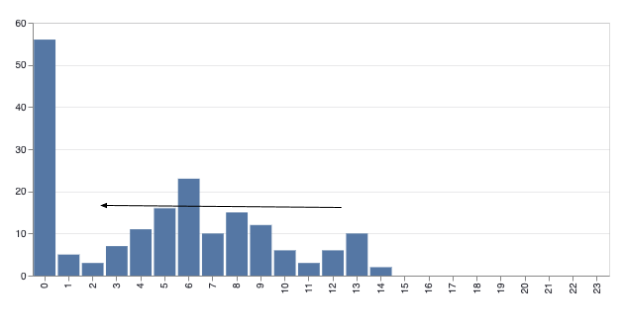
Perhaps this grouping is due to there being more people to “cleanup” low hanging fruit, the simple changes that are hanging around as there really aren’t enough people to take them on. The reality is rarely clear cut, but it is interesting to try and use data to help make decisions.
How to simulate adding people to work in progress
Adding people to work in progress is looking at the number of reviews, changes and assignments per person that are already known about in the system, and increasing it proportionally with the number of people we want to add. (When you add more people, they are going to interact with the system more). Simply put, when there are unassigned pull requests and review requests missing, adding people means they can be assigned to it. This adjustment affects the outcome of the prediction (which is now a simulation). It sounds complex, but it isn’t really that complicated to do when you have the data (which the CloudBees Software Delivery Management graphql database does). In the real world, you would probably get new people on to new tasks, instead of in-progress ones (and the above simulation suggests that would be better).
What else can we simulate?
The predictions for a pull request are based on data from a graphql database that connects the change to products, other repos, issues and more. All of these are “features” that help make a prediction and we can tweak them as we see fit to see what happens:
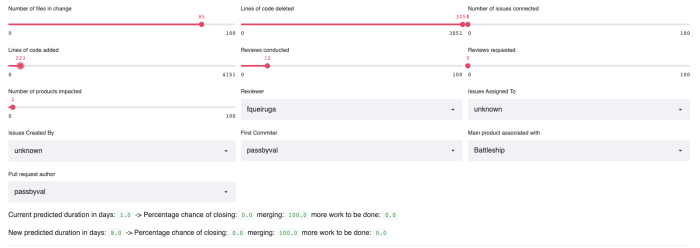
In the above case, I picked a pull request that had originally 4000+ lines of code changed and was predicted to merge soon. I reduced the lines of code in the change to the hundreds, and the new predictions for completed work was estimated to be eight days! This seems odd, but confirms a well known theory that when people see a very large change in a pull request, they don’t go over every line of code with a fine tooth comb. However, when the change is small, they do. Make of this what you will!
Conclusion
Adding people to a change doesn’t always help with work in progress, but it is more subtle than that in reality. You can do a lot with simulations that you can’t actually do in real world experiments. This kind of predictive analytics may help make informed decisions based on data, instead of just intuition.
It can be frustrating for those outside of an engineering organization to know what is going on or why things take so long. Predictions based on past data can help people have confidence that things are in an “ok” state. Exposing things in a simple way with generated summaries and ETA for work in progress may help an organisation feel more confident in their software delivery:

Next time I hope to dive more into this exciting world of language models, GPT-3 and explaining what is going on in your software delivery pipeline.


