
In some ways, version numbering schemes can be a lot like TABs vs Spaces or emacs vs vi. You know the kind of wars where the wrong people just keep on fighting even if TABs are evil and emacs is harder to quit than vi. What interests me, however, is that often there are really rather interesting reasons behind the choice of one version numbering scheme over another. In that context I thought it might be interesting to share with you our reasons for selecting the version numbering scheme we use internally for the CloudBees DevOptics components.
If reading a blog post is not your thing, you might be interested in this video I recorded on the same topic:
Do we even need version numbers?
If you are developing a pure website, where customers only interact using a web browser, there really isn't much exposed surface of your code.

You could probably get away with just exposing the Git commit hash as a version as it really only matters to the developers.
As we add features and complexity to our applications we start to discover some of the advantages of having version numbers. If we add a REST API to our website...

Now you are exposing not just to browsers but also to code that the customer has written to call the REST service. The customer may start to pressure you about the version of your REST API, so that they can find out what changed since the last time they updated their integration. You could probably get away with just exposing the last modified date as the version.
Your customers are having issues writing REST clients. They keep on adding the authorization headers incorrectly, so you decide to write a client library for them. Now you are shipping more than just the website, you are also shipping a REST API client library.

Now you ship two deliverables, one of which gets embedded in the customer's code. You have lost the ability to completely control what versions of your code are deployed in production at any one moment in time. You cannot control when the customers will update the client library you ship. You will need to introduce some version numbering scheme even if only to allow your technical support people to use the "What version are you running? Oh, could you try upgrading to the latest?" strategy of fixing!
What's wrong with Semver
I have expressed some strong opinions on this topic before. To be honest, there is nothing particularly wrong with Semver , rather it is just not universally applicable. Semver uses a three component scheme: MAJOR.MINOR.PATCH where you increment the:
- MAJOR version when you make incompatible API changes,
- MINOR version when you add functionality in a backwards-compatible manner, and
- PATCH version when you make backwards-compatible bug fixes.
Semver can be a good fit if you are developing a single module or library. When you have multiple modules, you either need to apply Semver independently to each one or apply Semver to the whole aggregate. When you marry this with the Git best practice of scoping the repository with the versioning lifecycle - basically only modules that share the same version numbers should be in the same Git repository.
In our case, for example, the Run Insights repository has at least three components:

We have data transfer objects that are used by both the REST client and the REST API backend. The data transfer objects almost never have a breaking change. We could host them in three separate repositories and manage their release lifecycle separately, but that gets rather complex to coordinate changes in what can be a very small DTO module.
Another issue with Semver for us is the current impossibility to automate Semver. Semver sounds like it would be simple:
increment the MAJOR version when you make incompatible API changes,
But the issue is how do you decide when an API change is incompatible. For sure, if you change method signatures and or class names that is an incompatible API change, and we probably could get tooling to help detect those cases... but an API is also its behaviour.
If the method stops accepting nulls that could be a breaking change for some customers... in fact if it starts accepting nulls and stops throwing a specific exception, that too could even be a breaking API change. Perhaps a specific sequence of calls now causes a different behaviour... all of these are incompatible API changes... but there is no generic tooling that will catch these changes and declare "we should make a major version bump".
We use Continuous Deployment in DevOptics, so we need a scheme that is robust to automation.
The final nail in the coffin of Semver for us is the fact that we have no control over when our customers will upgrade their plugins. So our services need to be backwards compatible. In essence, we actually cannot have an incompatible API change because of the customer impact.
Our choice
In the end we decided on the following scheme: EPOCH.COMMIT_COUNT.RELEASE_COUNT
- The EPOCH represents the version numbering scheme. For Run Insights, this is 1, but for the older Value Streams services - which had a previous version numbering scheme - this is 2. If we change version numbering scheme we will increase the EPOCH .
- The COMMIT_COUNT is the number of commits on the master branch of the canonical Git repository. We run all our releases from the CI/CD server which only builds from the canonical Git repositories. We have turned on GitHub's protected branches feature to prevent `git push --force from rewinding the commit count.
- The RELEASE_COUNT is normally 0 and omitted. If we need to re-run a release of a specific commit, we increase the RELEASE_COUNT by one for each re-run.
This versioning scheme has some useful properties for us:
- Numbers are less error prone than commit hashes. Consider how difficult to communicate "version 1.1205" compared with "version 7a42d0f89". If you are on a support call with a customer, it can be much easier to get a version number over an audio call.
- Our scheme allows as many versions in one day as we need. We could have used a Date based version number, but consider "version 1.1205" compared with "version 201902191642"... and even that limits us to one version per minute.
- The version number is strictly increasing, thus we know if one number is bigger then it is newer.
- The version number "jump" is reflective of the amount of change.
- The version is predictable, if you look on GitHub at the commit count:
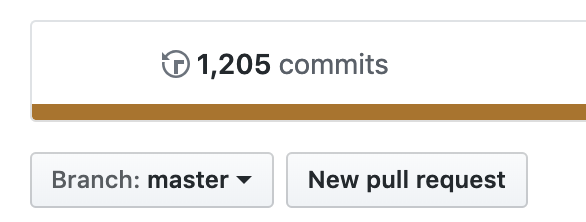
you can immediately know what the version number will be, i.e. 1205 commits will be version 1.1205. It can be exceedingly handy to mark JIRA issues as resolved in version 1.1205 without having to wait for the CI/CD deployment job to finish, thereby freeing you up to move onto your next task.
Conclusions
There's a lot to be said for the Semver version numbering scheme, but remember it isn't universally appropriate. Consider the functionality you wish to encode in your version numbers and then select your scheme.
Stephen Connolly has over 20 years experience in software development. He is involved in a number of open source projects, including Jenkins . Stephen was one of the first non-Sun committers to the Jenkins project and developed the weather icons. Stephen lives in Dublin, Ireland - where the weather icons are particularly useful. Follow Stephen on Twitter and on his blog .