

One of the principles of Docker containers is that an image is immutable -- once built, it’s unchangeable, and if you want to make changes, you’ll get a new image as a result. In this post, we’ll take a deep dive into the immutability of containers, and then we’ll look at some of the consequences and potential problems, as well as see how applying some metadata to your container images can really help.
Not got time for the details? TL;DR: use LABEL to add meaningful metadata to your container images, and you'll thank yourself in months to come!
Container Images and Immutability
You can modify a container, and you can create a new container image by "committing" the state of that container. But when you do that, you create a new image. The previous image is untouched. Let’s see how we do that with Docker.
I’m going to use an image called lizrice/imagetest, which is a very simple image based on Alpine that I’ve been using for metadata experiments. Feel free to use your own image if you prefer. For this example, I inspect my image as follows:
LANG:code
$ docker inspect lizrice/imagetest
The first line in the output is the identifier: a unique hash for this particular image that looks something like this:
LANG:code
"Id": "sha256:e9ea81af1e8d197fb083cc05e8d722233c0c4aab83deabc54adccd8a225a8b29"
This is the full-length hash. You’ll see that it matches the prefix that’s displayed if you run Docker images to list the images you have locally.
Now let’s create a container based on that image. In my example, I happen to not have a CMD directive in the Dockerfile. So I need to specify a command to run (even though it won’t get run at this point).
LANG:code
$ docker create lizrice/imagetest touch /nothing_to_see_here
The docker create command makes the container but doesn’t start it yet, so it won’t actually run the touch command yet. Eventually when we do run the container, the touch command will make a change to the file system of the container by creating a file called nothing_to_see_here. We’ll come to that very soon, but first let's take a look at the container and its status.
Because the container isn't running yet, we’ll need the -a flag to see it included in docker ps:
LANG:code
$ docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
306f4ba7c68a lizrice/imagetest "touch /nothing_to_se" 5 minutes ago Exited (0) 3 minutes ago grave_almeida
As you can see, the container is in Created status; it’s ready to run, but it’s not actually running yet. We can inspect it at this stage.
LANG:code
$ docker inspect 306f4ba7c68a
This generates quite a bit of output, including the image that this container is based on. As expected, you should see this is exactly the same identifier SHA that we saw as the ID of the container image:
LANG:code
"Image": "sha256:e9ea81af1e8d197fb083cc05e8d722233c0c4aab83deabc54adccd8a225a8b29"
Now let’s start the container. This is the point at which that touch command will get run.
LANG:code
$ docker start grave_almeida
The container starts up, runs the touch command, and then exits. We can see the change that this made on the file system by running docker diff.
LANG:code
$ docker diff grave_almeida
A /nothing_to_see_here
If we inspect the container, we can see that it’s still based on the same image ID (the one beginning with e9ea81). If we want to save this as a container image, we can do this with docker commit.
LANG:yaml
$ docker commit grave_almeida
sha256:8b76eee48c6c1e9373d321c99c8bbd80bb3f606c848d639280cce3395073807f
The SHA that has been output is the identifier for a new container image, which we can see included in the list of container images. We haven't modified our original image in any way.
LANG:html
$ docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
<none> <none> 8b76eee48c6c 7 seconds ago 4.805 MB
lizrice/imagetest latest e9ea81af1e8d About an hour ago 4.805 MB
The new image doesn’t have any repository or tag information associated with it. We can use the docker tag command to add this, but let’s say, for the sake of argument, that we got distracted and forgot to do that.

Working Out What the Image Is
If you’ve been working with Docker for more than about ten minutes, you’ll know how quickly you can build up containers and container images. You might even be surprised by how many you have sitting on your machine if you run docker ps -a (to list all the containers) and docker images. And you might well find a fair few with those rather stark <none> entries for repo and tag.
Note: When your local Docker environment gets cluttered with unused containers, you can stop and remove all Docker containers at once to keep things clean and manageable. If a container is unresponsive, you can kill all containers.
If you haven’t tagged those images with a repo name, how on earth can you find out what code is inside them? As we’ve seen, you can inspect an image to get its ID, but unless you have a list of what the image IDs are, how useful is that?
Labels to the rescue
One solution, and a good practice in general, is to use Labels. Labels are simply key-value pairs that can be applied to images at build time or added when you start a container. You can use them to add meaningful metadata that can be invaluable in managing your containers and metadata.
I’m one of the authors of a community initiative called Label Schema, which offers some conventions for the keys to use in your labels. As I write, there are over 500 public images whose maintainers have already adopted these conventions.
The most basic of labels that can help us with our image identification problem is to give the image a name with the following line in the Dockerfile:
LANG:code
LABEL org.label-schema.name=’imagetest’
This means that my image will be built including this key-value pair, which I can see as part of the inspection process.
LANG:code
$ docker inspect lizrice/imagetest
"Labels": {
"org.label-schema.name": "imagetest"
}
How does this help?
Labels are inherited from ancestor images. So when you do a Docker commit as we did earlier, any labels from the original image will also exist in the new one. Inspect that new image, or a container based on that image, you’ll see the same labels have been inherited.
Labels are also inherited from the base image specified in the FROM directive in a Dockerfile. You can see this in action by using MicroBadger to look at the metadata from my example image lizrice/childimage.
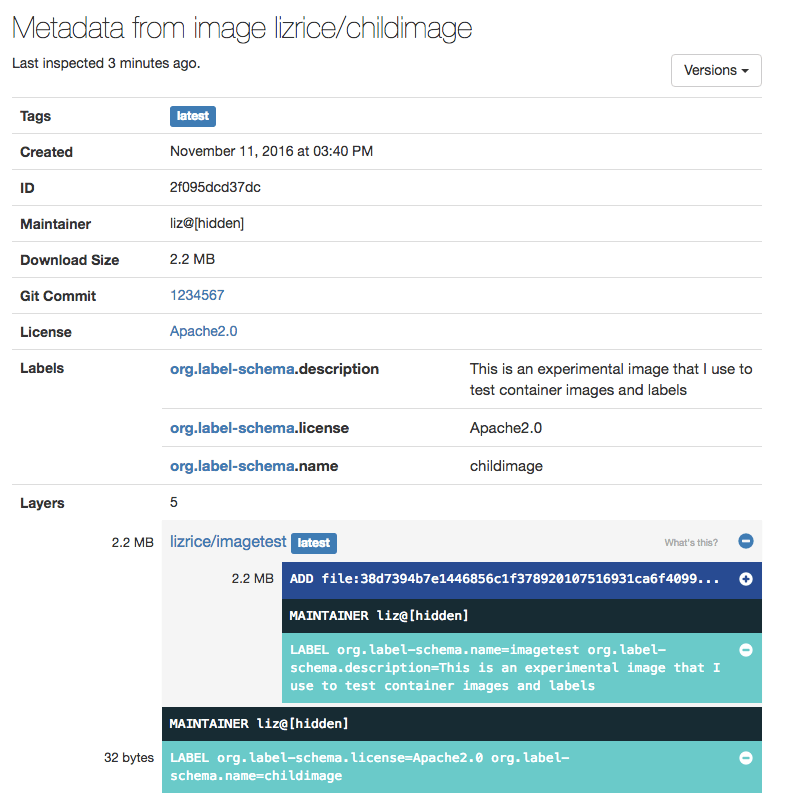
You can see this (experimental!) image has three labels:
- org.label-schema.description
- org.label-schema.license
- org.label-schema.name
But the “layer inspection” part shows us that lizrice/childimage is based on lizrice/imagetest, which contains three layers, including one with a LABEL directive. If we look carefully, we’ll see that the description was inherited from the parent image. The other two labels were added in the build of lizrice/childimage. In fact, the name label overwrites the name from the base image.
What metadata should I apply?
The Label Schema project offers some suggestions for useful labels. A few highlights that you might like to consider include:
- The git repository and commit reference, so you can see exactly what code was built into an image
- A URL for getting more information about this image
- A vendor field, helpful if you’re supplying your code to users as a container image
The Future of Metadata
So far, we’ve simply considered what’s happening when you build and run containers on your local machine. Now let’s think about the potential scale of an image management problem in the context of a continuous build environment like Codeship.
Let’s suppose you work for a company with a hundred engineers. Even if they only each push a commit a couple of times per day, that’s 1,000 new image builds every week. You’ll have hundreds of thousands of images to deal with in just a couple of years!
How do you keep track of which of those images are useful? Can you easily tell from your logging or monitoring solutions exactly which container images are deployed? Which ones are in test? How do you get in touch with the support contact for a container that’s generating a ton of logs in the live production system? All these questions and many more become significantly more difficult to cope with when you’re dealing with a large number of images.
These are all problems that container metadata can help with, especially with the benefit of conventions on how we all label our images.
For example, logging and visualization tools can use common Label Schema conventions to make it easier to identify the code that a container is running. We’re expecting to see an explosion in the use of metadata, and some real improvements in usability as tools evolve to help manage our containers.


