
This is part of a series of blog posts in which various CloudBees technical experts have summarized presentations from the Jenkins User Conferences (JUC). This post is written by Harpreet Singh, VP product management, CloudBees about a presentation given by Kohsuke Kawaguchi from CloudBees at JUC Boston .
A talk by Kohsuke Kawaguchi is always exciting. It gets triply exciting when his talk bundles three in one.
Scaling Jenkins horizontally
Kohsuke outlined the case on how organizations scale, either vertically or organically (numerous Jenkins controllers abound in the organization). He made the case that the way forward is to scale horizontally. In this approach a Jenkins Operations Center by CloudBees controller manages multiple Jenkins in the organizations. This approach helps organizations share resources (agents) and have a unified security model through roles-based access control plugin from CloudBees.
Jenkins Operations Center by CloudBees
This architecture lets administrators maintain a few big Jenkins controllers that can be managed by the operations center. This effectively builds an infrastructure that fails less and recovers from failures faster.
Right sized Jenkins controllers
Bursting to the cloud (through CloudBees DEV@cloud)
He then switched gear to address a use case where teams can start using cloud resources when they run out of build capacity on their local build farm. He walked through the underlying technological pieces built at CloudBees using LXC.
 |
| CloudBursting: Supported by LXC containers on CloudBees |
The neat thing with the above technology piece is that we have used it to offer OSX build agents in the cloud.
We have an article [2] highlights on how to use cloud bursting with CloudBees. The key advantage is that users pay for builds-by-the-minute.
Traceability
Organizations are looking at continuous delivery to deliver software often. They often use Jenkins to build binaries and use tools such as Puppet and Chef to deploy these binaries in production. However, if something does go wrong in production environment, it is quite a challenge to tie these back to the commit that caused issues. The traceability work in Jenkins ties this loose end. So post deployment, Puppet/Chef notifies a Jenkins plugin and Jenkins calculates its finger print and maintains it in the internal database. This fingerprint can be used to track where the commits have landed and help diagnose failures faster. We have an article [3] that describes how to set this up with Puppet.
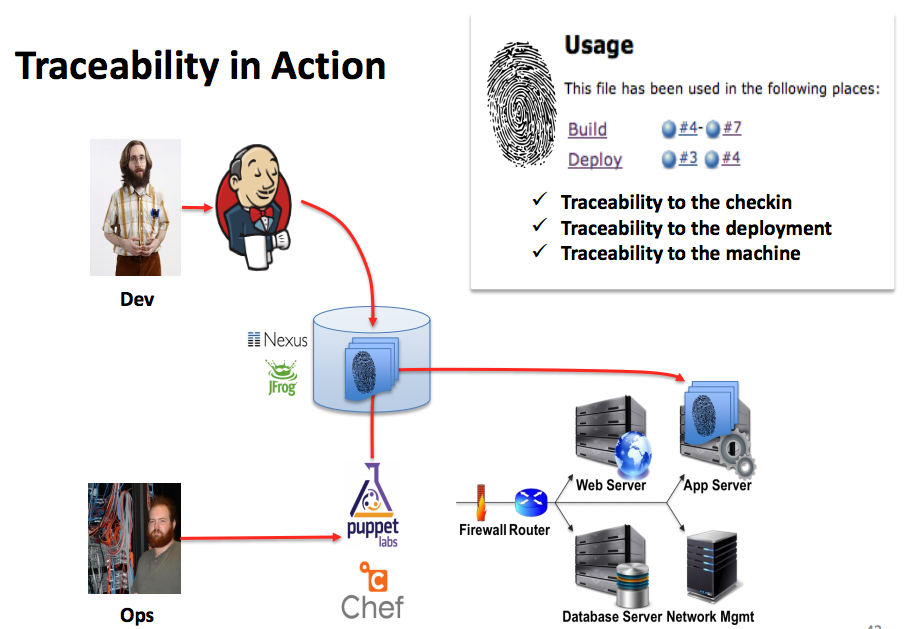 |
| Finger prints flow through Jenkins, Puppet and Chef |
[1] Jenkins Operations Center by CloudBees
[2] Bursting to the cloud
[3] Traceability example
-- Harpreet Singh
Harpreet is vice president of product management at CloudBees.
Follow Harpreet on Twitter .